-
1. Começando
- 1.1 Sobre Controle de Versão
- 1.2 Uma Breve História do Git
- 1.3 O Básico do Git
- 1.4 A Linha de Comando
- 1.5 Instalar o Git
- 1.6 Configuração Inicial do Git
- 1.7 Pedindo Ajuda
- 1.8 Resumo
-
2. Noções Básicas do Git
- 2.1 Obtendo um Repositório Git
- 2.2 Recording Changes to the Repository
- 2.3 Veja o Histórico de Confirmação
- 2.4 Desfazer Coisas
- 2.5 Working with Remotes
- 2.6 Tagging
- 2.7 Alias Git
- 2.8 Resumo
-
3. Ramificação do Git
- 3.1 Branches in a Nutshell
- 3.2 Basic Branching and Merging
- 3.3 Branch Management
- 3.4 Branching Workflows
- 3.5 Remote Branches
- 3.6 Rebasing
- 3.7 Resume
-
4. Git no Servidor
- 4.1 The Protocols
- 4.2 Getting Git on a Server
- 4.3 Generating Your SSH Public Key
- 4.4 Setting Up the Server
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Opções Hospedadas de Terceiros
- 4.10 Resumo
-
5. Git Distribuído
- 5.1 Distributed Workflows
- 5.2 Contributing to a Project
- 5.3 Maintaining a Project
- 5.4 Resumo
-
6. GitHub
-
7. Ferramentas do Git
- 7.1 Revision Selection
- 7.2 Interactive Staging
- 7.3 Stashing and Cleaning
- 7.4 Signing Your Work
- 7.5 Searching
- 7.6 Rewriting History
- 7.7 Reset Demystified
- 7.8 Advanced Merging
- 7.9 Rerere
- 7.10 Debugging with Git
- 7.11 Submodules
- 7.12 Bundling
- 7.13 Replace
- 7.14 Credential Storage
- 7.15 Resumo
-
8. Personalizar o Git
- 8.1 Git Configuration
- 8.2 Git Attributes
- 8.3 Git Hooks
- 8.4 An Example Git-Enforced Policy
- 8.5 Resumo
-
9. O Git e Outros Sistemas
- 9.1 O Git como Cliente
- 9.2 Migrar para o Git
- 9.3 Resumo
-
10. Internos do Git
- 10.1 Plumbing and Porcelain
- 10.2 Git Objects
- 10.3 Git References
- 10.4 Packfiles
- 10.5 The Refspec
- 10.6 Transfer Protocols
- 10.7 Maintenance and Data Recovery
- 10.8 Environment Variables
- 10.9 Resumo
-
A1. Appendix A: Git em Outros Ambientes
- A1.1 Graphical Interfaces
- A1.2 Git no Visual Studio
- A1.3 Git no Eclipse
- A1.4 Git in Bash
- A1.5 Git no Zsh
- A1.6 Git no Powershell
- A1.7 Resumo
-
A2. Appendix B: Incorporar o Git nos teus Aplicativos
- A2.1 Linha de comando Git
- A2.2 Libgit2
- A2.3 JGit
-
A3. Appendix C: Git Commands
- A3.1 Setup and Config
- A3.2 Getting and Creating Projects
- A3.3 Basic Snapshotting
- A3.4 Branching and Merging
- A3.5 Sharing and Updating Projects
- A3.6 Inspection and Comparison
- A3.7 Debugging
- A3.8 Patching
- A3.9 Email
- A3.10 External Systems
- A3.11 Administration
- A3.12 Plumbing Commands
2.2 Noções Básicas do Git - Recording Changes to the Repository
Recording Changes to the Repository
At this point, you should have a bona fide Git repository on your local machine, and a checkout or working copy of all of its files in front of you. Typically, you’ll want to start making changes and committing snapshots of those changes into your repository each time the project reaches a state you want to record.
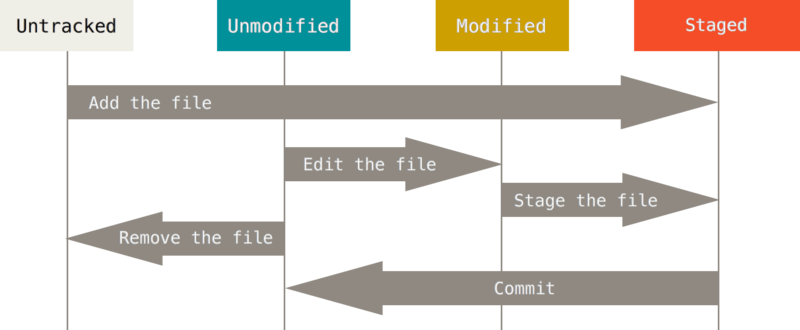
Remember that each file in your working directory can be in one of two states: tracked or untracked. Tracked files are files that were in the last snapshot; they can be unmodified, modified, or staged. In short, tracked files are files that Git knows about.
Untracked files are everything else — any files in your working directory that were not in your last snapshot and are not in your staging area. When you first clone a repository, all of your files will be tracked and unmodified because Git just checked them out and you haven’t edited anything.
As you edit files, Git sees them as modified, because you’ve changed them since your last commit. As you work, you selectively stage these modified files and then commit all those staged changes, and the cycle repeats.
Checking the Status of Your Files
The main tool you use to determine which files are in which state is the git status command.
If you run this command directly after a clone, you should see something like this:
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
nothing to commit, working directory cleanThis means you have a clean working directory — in other words, none of your tracked files are modified. Git also doesn’t see any untracked files, or they would be listed here. Finally, the command tells you which branch you’re on and informs you that it has not diverged from the same branch on the server. For now, that branch is always “master”, which is the default; you won’t worry about it here. Ramificação do Git will go over branches and references in detail.
Let’s say you add a new file to your project, a simple README file.
If the file didn’t exist before, and you run git status, you see your untracked file like so:
$ echo 'My Project' > README
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Untracked files:
(use "git add <file>..." to include in what will be committed)
README
nothing added to commit but untracked files present (use "git add" to track)You can see that your new README file is untracked, because it’s under the “Untracked files” heading in your status output.
Untracked basically means that Git sees a file you didn’t have in the previous snapshot (commit); Git won’t start including it in your commit snapshots until you explicitly tell it to do so.
It does this so you don’t accidentally begin including generated binary files or other files that you did not mean to include.
You do want to start including README, so let’s start tracking the file.
Tracking New Files
In order to begin tracking a new file, you use the command git add.
To begin tracking the README file, you can run this:
$ git add READMEIf you run your status command again, you can see that your README file is now tracked and staged to be committed:
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: READMEYou can tell that it’s staged because it’s under the “Changes to be committed” heading.
If you commit at this point, the version of the file at the time you ran git add is what will be in the historical snapshot.
You may recall that when you ran git init earlier, you then ran git add <files> — that was to begin tracking files in your directory.
The git add command takes a path name for either a file or a directory; if it’s a directory, the command adds all the files in that directory recursively.
Staging Modified Files
Let’s change a file that was already tracked.
If you change a previously tracked file called CONTRIBUTING.md and then run your git status command again, you get something that looks like this:
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: CONTRIBUTING.mdThe CONTRIBUTING.md file appears under a section named “Changes not staged for commit” — which means that a file that is tracked has been modified in the working directory but not yet staged.
To stage it, you run the git add command.
git add is a multipurpose command — you use it to begin tracking new files, to stage files, and to do other things like marking merge-conflicted files as resolved.
It may be helpful to think of it more as “add precisely this content to the next commit” rather than “add this file to the project”.
Let’s run git add now to stage the CONTRIBUTING.md file, and then run git status again:
$ git add CONTRIBUTING.md
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README
modified: CONTRIBUTING.mdBoth files are staged and will go into your next commit.
At this point, suppose you remember one little change that you want to make in CONTRIBUTING.md before you commit it.
You open it again and make that change, and you’re ready to commit.
However, let’s run git status one more time:
$ vim CONTRIBUTING.md
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README
modified: CONTRIBUTING.md
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: CONTRIBUTING.mdWhat the heck?
Now CONTRIBUTING.md is listed as both staged and unstaged.
How is that possible?
It turns out that Git stages a file exactly as it is when you run the git add command.
If you commit now, the version of CONTRIBUTING.md as it was when you last ran the git add command is how it will go into the commit, not the version of the file as it looks in your working directory when you run git commit.
If you modify a file after you run git add, you have to run git add again to stage the latest version of the file:
$ git add CONTRIBUTING.md
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README
modified: CONTRIBUTING.mdShort Status
While the git status output is pretty comprehensive, it’s also quite wordy.
Git also has a short status flag so you can see your changes in a more compact way.
If you run git status -s or git status --short you get a far more simplified output from the command:
$ git status -s
M README
MM Rakefile
A lib/git.rb
M lib/simplegit.rb
?? LICENSE.txtNew files that aren’t tracked have a ?? next to them, new files that have been added to the staging area have an A, modified files have an M and so on.
There are two columns to the output - the left-hand column indicates the status of the staging area and the right-hand column indicates the status of the working tree.
So for example in that output, the README file is modified in the working directory but not yet staged, while the lib/simplegit.rb file is modified and staged.
The Rakefile was modified, staged and then modified again, so there are changes to it that are both staged and unstaged.
Ignoring Files
Often, you’ll have a class of files that you don’t want Git to automatically add or even show you as being untracked.
These are generally automatically generated files such as log files or files produced by your build system.
In such cases, you can create a file listing patterns to match them named .gitignore.
Here is an example .gitignore file:
$ cat .gitignore
*.[oa]
*~The first line tells Git to ignore any files ending in “.o” or “.a” — object and archive files that may be the product of building your code.
The second line tells Git to ignore all files whose names end with a tilde (~), which is used by many text editors such as Emacs to mark temporary files.
You may also include a log, tmp, or pid directory; automatically generated documentation; and so on.
Setting up a .gitignore file for your new repository before you get going is generally a good idea so you don’t accidentally commit files that you really don’t want in your Git repository.
The rules for the patterns you can put in the .gitignore file are as follows:
-
Blank lines or lines starting with
#are ignored. -
Standard glob patterns work, and will be applied recursively throughout the entire working tree.
-
You can start patterns with a forward slash (
/) to avoid recursivity. -
You can end patterns with a forward slash (
/) to specify a directory. -
You can negate a pattern by starting it with an exclamation point (
!).
Glob patterns are like simplified regular expressions that shells use.
An asterisk (*) matches zero or more characters; [abc] matches any character inside the brackets (in this case a, b, or c); a question mark (?) matches a single character; and brackets enclosing characters separated by a hyphen ([0-9]) matches any character between them (in this case 0 through 9).
You can also use two asterisks to match nested directories; a/**/z would match a/z, a/b/z, a/b/c/z, and so on.
Here is another example .gitignore file:
# ignore all .a files
*.a
# but do track lib.a, even though you're ignoring .a files above
!lib.a
# only ignore the TODO file in the current directory, not subdir/TODO
/TODO
# ignore all files in the build/ directory
build/
# ignore doc/notes.txt, but not doc/server/arch.txt
doc/*.txt
# ignore all .pdf files in the doc/ directory and any of its subdirectories
doc/**/*.pdf|
Tip
|
GitHub maintains a fairly comprehensive list of good |
|
Note
|
In the simple case, a repository might have a single It is beyond the scope of this book to get into the details of multiple |
Viewing Your Staged and Unstaged Changes
If the git status command is too vague for you — you want to know exactly what you changed, not just which files were changed — you can use the git diff command.
We’ll cover git diff in more detail later, but you’ll probably use it most often to answer these two questions: What have you changed but not yet staged?
And what have you staged that you are about to commit?
Although git status answers those questions very generally by listing the file names, git diff shows you the exact lines added and removed — the patch, as it were.
Let’s say you edit and stage the README file again and then edit the CONTRIBUTING.md file without staging it.
If you run your git status command, you once again see something like this:
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: README
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: CONTRIBUTING.mdTo see what you’ve changed but not yet staged, type git diff with no other arguments:
$ git diff
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 8ebb991..643e24f 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -65,7 +65,8 @@ branch directly, things can get messy.
Please include a nice description of your changes when you submit your PR;
if we have to read the whole diff to figure out why you're contributing
in the first place, you're less likely to get feedback and have your change
-merged in.
+merged in. Also, split your changes into comprehensive chunks if your patch is
+longer than a dozen lines.
If you are starting to work on a particular area, feel free to submit a PR
that highlights your work in progress (and note in the PR title that it'sThat command compares what is in your working directory with what is in your staging area. The result tells you the changes you’ve made that you haven’t yet staged.
If you want to see what you’ve staged that will go into your next commit, you can use git diff --staged.
This command compares your staged changes to your last commit:
$ git diff --staged
diff --git a/README b/README
new file mode 100644
index 0000000..03902a1
--- /dev/null
+++ b/README
@@ -0,0 +1 @@
+My ProjectIt’s important to note that git diff by itself doesn’t show all changes made since your last commit — only changes that are still unstaged.
If you’ve staged all of your changes, git diff will give you no output.
For another example, if you stage the CONTRIBUTING.md file and then edit it, you can use git diff to see the changes in the file that are staged and the changes that are unstaged.
If our environment looks like this:
$ git add CONTRIBUTING.md
$ echo '# test line' >> CONTRIBUTING.md
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: CONTRIBUTING.md
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: CONTRIBUTING.mdNow you can use git diff to see what is still unstaged:
$ git diff
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 643e24f..87f08c8 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -119,3 +119,4 @@ at the
## Starter Projects
See our [projects list](https://github.com/libgit2/libgit2/blob/development/PROJECTS.md).
+# test lineand git diff --cached to see what you’ve staged so far (--staged and --cached are synonyms):
$ git diff --cached
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 8ebb991..643e24f 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -65,7 +65,8 @@ branch directly, things can get messy.
Please include a nice description of your changes when you submit your PR;
if we have to read the whole diff to figure out why you're contributing
in the first place, you're less likely to get feedback and have your change
-merged in.
+merged in. Also, split your changes into comprehensive chunks if your patch is
+longer than a dozen lines.
If you are starting to work on a particular area, feel free to submit a PR
that highlights your work in progress (and note in the PR title that it's|
Note
|
Git Diff in an External Tool
We will continue to use the |
Committing Your Changes
Now that your staging area is set up the way you want it, you can commit your changes.
Remember that anything that is still unstaged — any files you have created or modified that you haven’t run git add on since you edited them — won’t go into this commit.
They will stay as modified files on your disk.
In this case, let’s say that the last time you ran git status, you saw that everything was staged, so you’re ready to commit your changes.
The simplest way to commit is to type git commit:
$ git commitDoing so launches your editor of choice.
(This is set by your shell’s EDITOR environment variable — usually vim or emacs, although you can configure it with whatever you want using the git config --global core.editor command as you saw in Começando).
The editor displays the following text (this example is a Vim screen):
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
# On branch master
# Your branch is up-to-date with 'origin/master'.
#
# Changes to be committed:
# new file: README
# modified: CONTRIBUTING.md
#
~
~
~
".git/COMMIT_EDITMSG" 9L, 283CYou can see that the default commit message contains the latest output of the git status command commented out and one empty line on top.
You can remove these comments and type your commit message, or you can leave them there to help you remember what you’re committing.
(For an even more explicit reminder of what you’ve modified, you can pass the -v option to git commit.
Doing so also puts the diff of your change in the editor so you can see exactly what changes you’re committing.)
When you exit the editor, Git creates your commit with that commit message (with the comments and diff stripped out).
Alternatively, you can type your commit message inline with the commit command by specifying it after a -m flag, like this:
$ git commit -m "Story 182: Fix benchmarks for speed"
[master 463dc4f] Story 182: Fix benchmarks for speed
2 files changed, 2 insertions(+)
create mode 100644 READMENow you’ve created your first commit!
You can see that the commit has given you some output about itself: which branch you committed to (master), what SHA-1 checksum the commit has (463dc4f), how many files were changed, and statistics about lines added and removed in the commit.
Remember that the commit records the snapshot you set up in your staging area. Anything you didn’t stage is still sitting there modified; you can do another commit to add it to your history. Every time you perform a commit, you’re recording a snapshot of your project that you can revert to or compare to later.
Skipping the Staging Area
Although it can be amazingly useful for crafting commits exactly how you want them, the staging area is sometimes a bit more complex than you need in your workflow.
If you want to skip the staging area, Git provides a simple shortcut.
Adding the -a option to the git commit command makes Git automatically stage every file that is already tracked before doing the commit, letting you skip the git add part:
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: CONTRIBUTING.md
no changes added to commit (use "git add" and/or "git commit -a")
$ git commit -a -m 'added new benchmarks'
[master 83e38c7] added new benchmarks
1 file changed, 5 insertions(+), 0 deletions(-)Notice how you don’t have to run git add on the CONTRIBUTING.md file in this case before you commit.
That’s because the -a flag includes all changed files.
This is convenient, but be careful; sometimes this flag will cause you to include unwanted changes.
Removing Files
To remove a file from Git, you have to remove it from your tracked files (more accurately, remove it from your staging area) and then commit.
The git rm command does that, and also removes the file from your working directory so you don’t see it as an untracked file the next time around.
If you simply remove the file from your working directory, it shows up under the “Changes not staged for commit” (that is, unstaged) area of your git status output:
$ rm PROJECTS.md
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
deleted: PROJECTS.md
no changes added to commit (use "git add" and/or "git commit -a")Then, if you run git rm, it stages the file’s removal:
$ git rm PROJECTS.md
rm 'PROJECTS.md'
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
deleted: PROJECTS.mdThe next time you commit, the file will be gone and no longer tracked.
If you modified the file and added it to the staging area already, you must force the removal with the -f option.
This is a safety feature to prevent accidental removal of data that hasn’t yet been recorded in a snapshot and that can’t be recovered from Git.
Another useful thing you may want to do is to keep the file in your working tree but remove it from your staging area.
In other words, you may want to keep the file on your hard drive but not have Git track it anymore.
This is particularly useful if you forgot to add something to your .gitignore file and accidentally staged it, like a large log file or a bunch of .a compiled files.
To do this, use the --cached option:
$ git rm --cached READMEYou can pass files, directories, and file-glob patterns to the git rm command.
That means you can do things such as:
$ git rm log/\*.logNote the backslash (\) in front of the *.
This is necessary because Git does its own filename expansion in addition to your shell’s filename expansion.
This command removes all files that have the .log extension in the log/ directory.
Or, you can do something like this:
$ git rm \*~This command removes all files whose names end with a ~.
Moving Files
Unlike many other VCS systems, Git doesn’t explicitly track file movement. If you rename a file in Git, no metadata is stored in Git that tells it you renamed the file. However, Git is pretty smart about figuring that out after the fact — we’ll deal with detecting file movement a bit later.
Thus it’s a bit confusing that Git has a mv command.
If you want to rename a file in Git, you can run something like:
$ git mv file_from file_toand it works fine. In fact, if you run something like this and look at the status, you’ll see that Git considers it a renamed file:
$ git mv README.md README
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
renamed: README.md -> READMEHowever, this is equivalent to running something like this:
$ mv README.md README
$ git rm README.md
$ git add READMEGit figures out that it’s a rename implicitly, so it doesn’t matter if you rename a file that way or with the mv command.
The only real difference is that git mv is one command instead of three — it’s a convenience function.
More importantly, you can use any tool you like to rename a file, and address the add/rm later, before you commit.